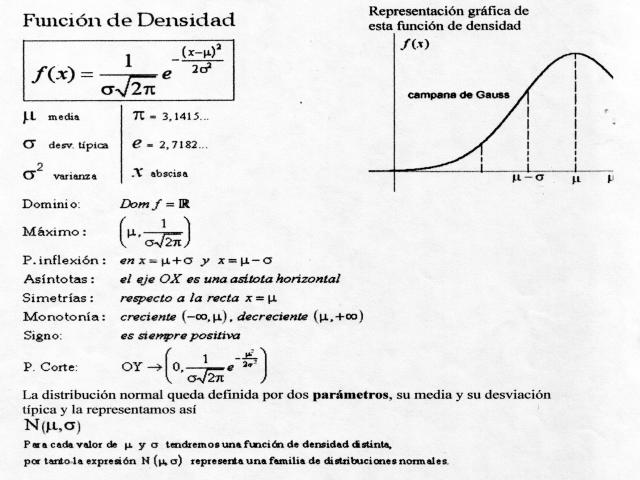
- Puede tomar cualquier valor (- ∞ ,+ ∞ )
- Son más probables los valores cercanos a uno central que llamados media
- Conforme nos separamos de ese valor µ , la probabilidad va decreciendo de igual forma a derecha e izquierda (es simétrica).
- Conforma nos separamos de ese valor µ , la probabilidad va decreciendo de forma más o menos rápida dependiendo de un parámetro s , que es la desviación típica.
La Distribución Binomial
Funciones de probabilidad:
Llamamos función d probabilidad f a la aplicación de E(X) (Espacio Muestral) en el intervalo [0,1] QUE VERIFICA:
f(A)= p (A)
Básicamente se trata de estudiar la probabilidad como una función utilizando para su estudio todas las propiedades de las funciones.
La Distribucion Binomial:
Llamamos experiencia aleatoria dicotómica a aquella que solo puede tener dos posibles resultados A y A'. Usualmente A recibe el nombre de éxito, además representaremos como p= p(A) y q=1-p=p(A’).
A la función de probabilidad de una variable aleatoria X resultado de contar el número de éxitos al repetir n veces una experiencia aleatoria dicotómica con probabilidad de éxito p la llamamos distribución binomial y la representamos por B (n, p)
Para esta distribución se verifica que, la variable X puede tomar los valores:
0,1,2,…, n
y que la variable toma cada uno de estos valores con probabilidad:
p( X = r ) = (nr) pr (1 – p) n-r
Parámetros de una distribución binomial:
Esperanza: n · p
Desviación típica (n · p · q )0.5 ( raíz cuadrada)
Ajuste de una serie de datos a una distribución binomial:
Disponemos de una serie de k datos que toman los valores 0,1, … ,n.
Para saber si estos datos siguen pueden aproximarse por una distribución binomial:
Calculamos la media de los k datos y la igualamos a la Esperanza teórica de la Binomial (n · p).
Despejamos de aquí el valor de p.
Calculamos los valores teóricos de p(X = r), multiplicándolos por k para obtener los valores teóricos de cada posible valor de la variable aleatoria en series de k datos.
Si la diferencia es " suficientemente pequeña " aceptamos como buena la aproximación Binomial, si no, la rechazamos.
(nota: la fundamentación estadística que nos permitiría decidir de manera objetiva si la diferencia entre los datos teóricos y los reales es "suficientemente pequeña" escapa de los objetivos de esta unidad didáctica, con lo cual la decisión se deberá tomar de manera subjetiva)
Muestreo
En estadística, es el proceso por el cual se seleccionan los individuos que formarán una muestra.
Para que se puedan obtener conclusiones fiables para la población a partir de la muestra, es importante tanto su tamaño como
el modo en que han sido seleccionados los individuos que la componen.
El tamaño de la muestra depende de la precisión que se quiera conseguir en la estimación que se realice a partir de ella. Para su determinación se requieren técnicas estadísticas superiores, pero resulta sorprendente cómo, con muestras notablemente pequeñas, se pueden conseguir resultados suficientemente precisos. Por ejemplo, con muestras de unos pocos miles de personas se pueden estimar con muchísima precisión los resultados de unas votaciones en las que participarán decenas de millones de votantes.
Para seleccionar los individuos de la muestra es fundamental proceder aleatoriamente, es decir, decidir al azar qué individuos de entre toda la población forma parte de la muestra.
Si se procede como si de un sorteo se tratara, eligiendo directamente de la población sin ningún otro condicionante, el muestreo se llama aleatorio simple o irrestrictamente aleatorio.
Cuando la población se puede subdividir en clases (estratos) con características especiales, se puede mostrar de modo que el número de individuos de cada estrato en la muestra mantenga la proporción que existía en la población. Una vez fijado el número que corresponde a cada estrato, los individuos se designan aleatoriamente. Este tipo de muestreo se denomina aleatorio estratificado con asignación proporcional.
Las inferencias realizadas mediante muestras seleccionadas aleatoriamente están sujetas a errores, llamados errores de muestreo, que están controlados. Si la muestra está mal elegida - no es significativa - se producen errores sistemáticos no controlados.
Métodos De Muestreo
Existen dos métodos de muestreo:
El muestreo probabilístico y no probabilístico
Métodos de muestreo probabilístico
Los métodos de muestreo probabilísticas son aquéllos que se basan en el principio de equiprobabilidad. Es decir, aquellos en los que todos los individuos tienen la misma probabilidad de ser elegidos para formar parte de una muestra y, consiguientemente, todas las posibles muestras de tamaño n tienen la misma probabilidad de ser elegidas. Sólo estos métodos de muestreo probabilísticas nos aseguran la representatividad de la muestra extraída y son, por tanto, los más recomendables. Dentro de los métodos de muestreo probabilísticas encontramos los siguientes tipos:
Muestreo aleatorio simple
El procedimiento es el siguiente: 1) se asigna un número a cada individuo de la población y 2) a través de algún medio mecánico (bolas dentro de una bolsa, tablas de números aleatorios, números aleatorios generados con una calculadora u ordenador, etc.) se eligen tantos sujetos como sea necesario para completar el tamaño de muestra requerido.
Este procedimiento, atractivo por su simpleza, tiene poca o nula utilidad práctica cuando la población que estamos manejando es muy grande.
Muestreo aleatorio sistemático
Este procedimiento exige, como el anterior, numerar todos los elementos de la población, pero en lugar de extraer n números aleatorios solo se extrae uno. Se parte de ese número aleatorio i, que es un número elegido al azar, y los elementos que integran la muestras son los que ocupan los lugares i,i+k,i+2k,i+3k,…,i+(n-1)k, es decir se toman los individuos de k en k, siendo k el resultado de dividir el tamaño de la población entre el tamaño de la muestra: k=N/n. el número i que empleamos como punto de partida será un número al azar entre 1 y k.
El riesgo de este tipo de muestreo está en los casos en que se dan periodicidad constante (k) podemos introducir una homogeneidad que no se da en la población. Imaginemos que estamos seleccionando una muestra sobre listas de 10 individuos en los que los 5 primeros son varones y los últimos 5 son mujeres, si empleamos un muestreo aleatorio sistemático con k=10 siempre seleccionaríamos o sólo hombres o sólo mujeres, no podría haber una representación de los dos sexos.
Muestreo aleatorio estratificado.
Trata de obviar las dificultades que presentan los anteriores ya que simplifican los procesos y suelen reducir el error muestral para un tamaño dado de la muestra. Consiste en considerar categorías típicas diferentes entre sí (estratos) que poseen gran homogeneidad respecto a alguna característica (se puede estratificar, por ejemplo, según la profesión, el municipio de residencia, el sexo, el estado civil, etc.). Lo que se pretende con este tipo de muestreo es asegurarse de que todos los estratos de interés estarán representados adecuadamente en la muestra. Cada estrato funciona independientemente, pudiendo aplicarse dentro de ellos el muestreo aleatorio simple o el estratificado para elegir los elementos concretos que formarán parte de la muestra. En ocasiones las dificultades que plantean son demasiado grandes, pues exige un conocimiento detallado de la población. (tamaño geográfico, sexos, edades…).